Python中的高效的集合操作
Python中有两种可以遍历的容器类型。
- 序列类型:包含字符串、列表、元祖
- 映射(哈希)类型:包含字典、集合
序列类型是线性表,就像数组一样,是在内存中开辟一块连续空间,连续存储的,那么查找某个元素时就需要从头开始租个对比,因此序列的查询效率是O(n),即一个长度为n的序列查询一个变量是否在其中一般需要n次操作。
映射类型是散列表,是基于哈希(Hash)算法的,变量在映射中的存储位置是通过计算得出来的,存取时,通过Hash计算出其应该存放的位置,存入,查找时,通过Hash计算其存放的位置,取出,因此映射类型的查询效率是O(1),即无论数据量多大,查询永远只需要一次操作。
在Hash算法中,不同的变量计算出的位置是唯一的,而为了同一个变量每次计算出的位置不变,就要求变量是不可变的类型。
在Python中不可变的类型包括:None、数字(整型、浮点型、布尔型)、字符串、元祖,即可哈希的。而列表、字典、集合这些容器类型,长度是不固定的,因此是不可哈希的,即不可作为Hash的键。
Python的字典是一种非常典型的Hash类型(Java中称为HashMap),即由定长的key计算出地址存放value。因此字典的key支持None、数字(整型、浮点型、布尔型)、字符串、元祖。
以下都是合法的字典。
{'name': 'kevin', 'age': 12, 'skills': ['python', 'java']}
{1: 'kevin', 2: 'eric'}
{True: 1, False: 0, None: -1}
{('kevin', 'cn'): {'name': 'keviin', 'age': 12}}
当我们只需要存储key不需要value时就得到一个集合类型,如
s = {'hello', 'hi', 'how are you'}
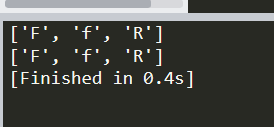
print(type(s))
打印出来是集合set类型。
注意:创建空集合不能用s = {},这样s是字典类型,空集合应使用s = set()创建。
身为一种哈希类型,集合中的元素同样要求是定长的,即可哈希的,支持None、数字(整型、浮点型、布尔型)、字符串、元祖几种类型,同时集合中的元素不可重复。
在日常使用中,相对于列表、字典来说集合的出镜率不高,然而通过集合可以高效的完成一些操作,如。
1.列表去重(注意会改变原有顺序)
l = [3,2,1,5,6,3,2,6,1,4]
l2 = list(set(l))
转为集合是会自动去重并排序,在转回列表得到[1, 2, 3, 4, 5, 6]。
2. 交集、并集、差集
这就是我们中学学的集合运算,在两组数据对比时是非常有效的,比如我们有两组数据。
l1 = ['kevin', 'eric', 'lily', 'niudun', 'sofia', 'lisi']
l2 = ['sofa', 'sofia', 'zhangsan', 'wangwu', 'lisi']
如何快速找出两者的差异呢?
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
# 转为集合
s1 = set(l1)
s2 = set(l2)
# 并集:两者中全部的,并去重
all = list(s1 | s2) # 得到 ['niudun', 'sofa', 'sofia', 'zhangsan', 'wangwu', 'lisi', 'lily', 'eric', 'kevin']
# 交集:两者重复的部分
same = list(s1 & s2) # 得到 ['lisi', 'sofia']
# 差集:l1中有l2没有的
diff = list(s1 - s2) # 得到 ['lily', 'eric', 'kevin', 'niudun'], 也可以`s2-s1`得到l2中有l1中没有的
同样,字典的.keys()得到的字典的所有键值是一种类似集合的类型,当字典每一个value值不包含可变类型(即没有嵌套列表、字典)时,字典的.items()方法同样支持集合操作。
d1 = {'name': 'kevin', 'age': 14, 'gender': 'male', 'class': 15, 'grade': 9, 'chinese': 94, 'math': 63, 'english': 82}
d2 = {'english': 82, 'age': 14, 'class': 15, 'chinese':94,'name': 'kevin', 'gender': 1, 'zhengzhi': 79, 'grade': 9}
假设我们要对比两组数据的不同
# d1中有d2中没有的key
d1.keys() - d2.keys() # 得到 {'math'}
# d2中有的d1中没有的key
d2.keys() - d1.keys() # 得到 {'zhengzhi'}
# d1中和d2中不同的项目
```python
d1.items() - d2.items() # {('math', 63), ('gender', 'male')}
d2.items() - d1.items() # {('zhengzhi', 79), ('gender', 1)}
使用.items()做集合操作时要求字典无嵌套列表、字典等可变类型